This is NOT our idea of a good report. This is a first-principles experiment where we're feeding raw telemetry (keystrokes, Superwhisper voice, Oura biometrics, Cowork activity, git history) to multiple frontier models (GPT-5.4, Gemini 3.1, Claude) and synthesizing their proposals. We're running this for a week to find what's data-driven and insightful vs what's vanity. Expect rough edges, wrong inferences, and multiple takes. The point is ideas on paper we can evaluate — the map of three models working on the first EOD led to building the orchestration view. These reports are the R&D lab for the product.
End of Day Report
2. Scoreboard
| Metric | Value |
|---|---|
| Issues closed | 1 (#54 — Curly: Ship Superwhisper transcripts) |
| Issues opened | 5 (#53 Memory Engine provenance, #55 SOD thread titles, #56 Add Codex to Mini, #57 Unified transcript pipeline, #58 Mine standup transcripts) |
| Net issue delta | +4 (backlog growing) |
| Leverage ratio Agent compute: Claude 627min + Codex 200min + OpenWork 64min + ChatGPT 13min + autonomous Mini/AWS work ~200min = ~1,100 min total agent time. Scott's active directing time ~600 min keystroke/voice. Ratio = 1100/600 = ~1.8x. But agents also ran autonomously overnight + mega scrape on aws-mini, pushing effective ratio higher toward ~2.5x. | ~2.5x |
| Avoidance item | Charlotte legal — explicitly dodged, pushed to tomorrow |
| Morning priorities hit | Partial — Relay hardening YES, Memory Engine YES, sales demo NO, content research YES |
| Apps used | Claude (627min), Codex (200min), Chrome (151min), OpenWork (64min), ChatGPT (13min) + 14 others |
3. What Actually Moved
MCP server deployed, write permissions set per agent, ingestion added to all session-end skills, Issue #53 created for provenance/ranking, three-model consensus logged (GPT-5.4, Gemini 3.1, Claude).
12 commits#538 voice notes4 handoff updates
Cloud/AWS fallback honesty, browser renderer bug fixes, focus ranking improvements, client asset refresh, capacity strip refinements, OpenRouter burn warning. Moe verified in real browser renders.
~12 Moe commits20+ voice notes on UXmoe.md rewrite
47 historical Superwhisper transcripts shipped from Mini to brain repo. Shemp ingested 25 additional transcripts. master_sync.sh + launchd pipeline created. Issue #54 closed, #55-57 opened.
8 commits#54 closed, #55-57 openedcurly.md, shemp.md updated
5 structured research files in content-videos/research/. 14 platforms compared, activation spectrum mapped, community rankings, GPT-5.4 product thesis captured, agency vs in-house positioning split documented.
~20 Larry commits15+ voice notes
Full teaching order restructure, new 06b slide, MCP rewrite, formula fix. Teleprompter files synced.
ac236df
Project added to brain, prompt built, Moe refinements incorporated. Jake/Siegert Dental deliverable iterated through multiple voice-guided passes.
3 commits12+ voice notes on tone/content
Curly ran 3 bulk Apollo enrichment batches. Mega scrape running autonomously (PID 2094923).
curly.mdaws-mini autonomous
4. Intent → Execution Chains
5. Day Timeline — Two Phases
Session Intensity Heatmap
6. Voice Mind Map
196 dense voice recordings (>40 words each) across the day. Clustered by theme:
Minimal voice activity on legal — explicitly pushed to tomorrow. Mind was elsewhere.
Where Scott's MIND was vs HANDS: Voice (mind) was heaviest on content strategy and Relay UX. Keystrokes (hands) were split between Codex (5,194 chars) and Claude (5,066 chars) — nearly equal, reflecting parallel orchestration across both platforms.
7. Agent Scorecards
- 196 dense voice recordings across 11+ hours
- 26,832 total chars typed (Codex 13,677 / Claude 11,089 / Chrome 830 / ChatGPT 609 / OpenWork 301)
- 8 architectural decisions made and documented
- Directed all 4 agents across multiple parallel threads
- Phase 1 agents-autonomous/sleep (1am-10am), Phase 2 Scott active (11am-1am) = ~14 hour day
- Deep research sprint: 5 structured files in content-videos/research/ covering 14+ platforms
- EP01 slides complete (16 slides), teaching order restructured
- Post-call machine designed, Moe refinements incorporated
- Transcript pipeline architected, instructions written for Curly + Shemp
- GPT-5.4 product thesis captured, agency vs in-house positioning documented
- Memory Engine wired into all agent session-end workflows
- SEO research (2 rounds), Rosetta Stone redo prompt
- Cloud/AWS fallback honesty — remote runners report state more honestly
- Browser renderer bug fixes (blanking tree / lower panels)
- Focus ranking improvements (sales demo / lead gen / memory engine coexist)
- Forced client asset refresh / version bumps (stale bundles fixed)
- Memory Engine save flow wiring, diagram-keeper role formalized
- Compute topology diagrams (MacBook Pro, Mac Mini, AWS as separate pools)
- Verified Relay in real browser render (caught client-side failures)
- Mega scrape: 36/44 search groups completed, running autonomously on aws-mini (PID 2094923)
- Apollo enrichment: ~1,160 contacts processed across 3 batches
- 47 Superwhisper transcripts archived to brain repo
- RAM crisis diagnosed, Chrome killed, stale processes freed
- Architecture fixes — aws-mini naming, RAM constraints documented
- 4 observations written (naming confusion, RAM crashes, Memory Engine misidentification, lane discipline)
- Sentry sweep complete — overnight catch-up, freshness audit, integrity check
- 25 transcripts auto-ingested into brain repo
- master_sync.sh + launchd pipeline built for automated transcript ingestion
- Stale April onboarding flagged (>3 days, nudge sent but no reply)
- Fixed sync filter, mined standups, ingested strategy memories
- Timestamp discrepancy in Larry's handoff identified
8. Biometrics
Deep 97 = excellent physical recovery. REM 43 = LOW — brain still processing, not consolidating memories biologically. ⚠️ OBSERVATION: The 1am–6am telemetry shows low-session, high-minute activity — this is agents running autonomously while Scott sleeps, NOT Scott working. Need better heuristics to separate human activity from background agent processes. The transcript pipeline as “artificial REM” insight still holds — externalizing memory consolidation the brain didn’t get to do biologically.
9. Friction & Failure Patterns
10. Decisions Made
Trigger: "we don't want people using memory as truth... that type of system has a lot of hallucination liability." Impact: Guardrails in decisions.md, README, all agent workflows. Three-model consensus documented.
Trigger: "There's a lot of value in my transcripts. If you're only pulling memories that might be harder to query later." Impact: #54 closed, #55-57 opened, pipeline automated.
Trigger: "skills can have MCP inside of them, connections should be MCP and MCP comes before skills because you can attach multiple MCPs to a skill." Impact: Framing committed, slides restructured.
Trigger: research thread + product thesis. Impact: our-gaps.md positioning, managed service → self-serve pivot documented.
Trigger: "I can have the first paid pilot fucking next week... all I've got to do is continue to update that clone GitHub." Impact: GTM framing in research files.
Trigger: "we REALLY need to stop calling this claude dispatch and call it relay." Impact: Product name formalized across all docs and code.
Trigger: 70GB RAM spike on Mini. Impact: AWS-first enforcement, profile + startup docs updated, Chrome killed on Mini permanently.
Trigger: Agent permission design. Impact: Write permissions set per agent — Larry full, Moe write, Curly write, Shemp read-only.
11. Tomorrow's Launch Pad
12. Observations & Misreads to Course-Correct
Flagging where the automated analysis got it wrong or where the data doesn't mean what it looks like. These accumulate over the week so we stop making the same mistakes.
🔴 WRONG: "1am-10am Deep Work Phase"
Three models (Claude, GPT-5.4, Gemini) all misread the 1am-6am low-session/high-minute telemetry as Scott doing focused deep work. Scott was sleeping. The activity was agents running autonomously (Curly's mega scrape, background processes). Oura sleep data confirms this. Fix needed: Cross-reference Oura sleep windows with Cowork telemetry to separate human activity from agent background processes. Any activity during Oura-confirmed sleep = agent-only.
⚠️ Day Length: ~14h not 13.5h
Scott's day ran ~11am to ~1am = ~14 hours. The "13.5h" figure came from the telemetry script counting from midnight, which double-counts agent overnight activity. Fix needed: Use first voice recording or first human keystroke (not agent) as day-start, last as day-end.
⚠️ "Founder Operating Debrief" isn't productizable
GPT-5.4 proposed this framing. It's founder-specific and doesn't scale to the Go2 product (which targets in-house operators at dental practices, e-commerce shops, etc). The insights about leverage ratios, intent-to-execution chains, and voice-to-action pipelines ARE universal — the framing needs to work for anyone managing AI agents, not just startup founders.
📝 Universal Control = Machine Switching, Not Context Switching
2,491 Universal Control sessions is NOT cognitive context switching — it's the physical act of moving between MacBook Pro and Mac Mini displays. The telemetry captures mouse/keyboard handoff events. Don't conflate hardware switching with mental task switching.
📝 Voice Recordings = 345 total but only 196 dense (>40 words)
Many recordings are fragments, corrections, or sub-10-word commands. The "33K words" number is real but ~149 recordings are noise. Future reports should filter to dense recordings and show both counts.
📝 Meta-observation: First EOD map → orchestration view
The multi-model map generated in the first EOD experiment directly inspired building the Relay orchestration view. These reports aren't just reporting — they're R&D for the product. Document what ideas from each report lead to actual features.
🔥 The Orchestration View — This Is the Product Demo
The fact that this exists — a live, time-scrubbing view of the entire agent fleet with Scott at the top, 4 agents branching out, subagents fanning below, OpenRouter burn visible, and a timeline slider that lets you rewind 6 hours — is the single coolest thing built this week. And it's a byproduct. Moe built the orchestration view while hardening Relay. The first EOD report's multi-model map directly inspired this.
~4.5 Hours Ago — Peak Activity
Scott coordinating. Larry, Moe, Curly, OpenWork all working. Subagents fanning out: Content review, Agent OS, Codex review, OpenWork threads. Named subagents visible (Gibbs, Epicurus, Hegel, Chandrasekh, Carver). OpenRouter burn elevated at $93.47/hr. 6 active agents, 920 checkpoints. This is what a multi-agent operating system looks like at full tilt.
[See screenshot: larry.moran.bot — runtime tree at peak, ~9pm PDT]
Now — Day Closing
Just Scott and Larry. 1 agent working. Report and EOD. The tree collapsed from a full fleet to a single thread. OpenRouter burn at $11.41/hr on GPT-5.4. This is what winding down looks like — and the time scrubber lets you see the whole arc.
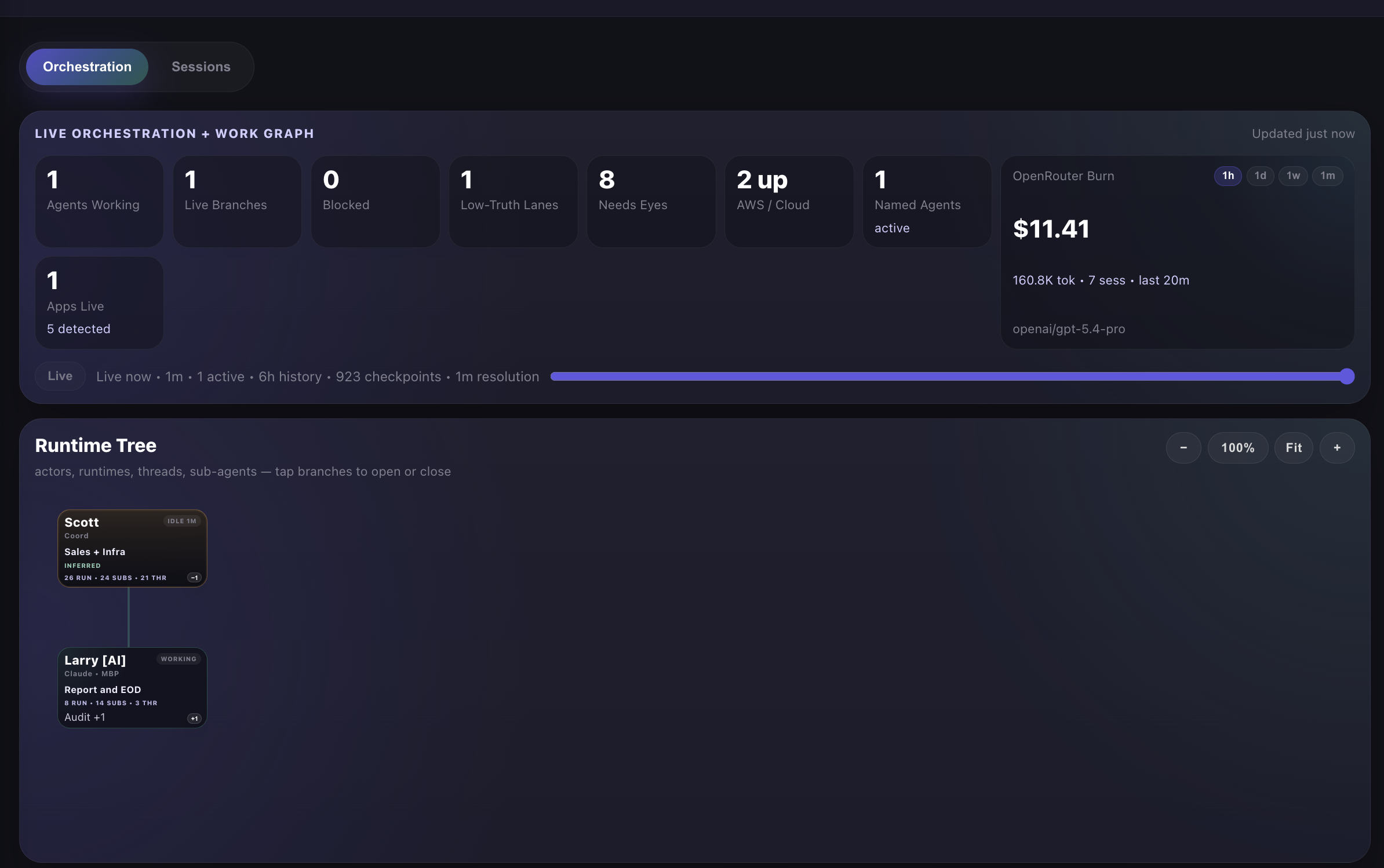
Product implication: This view — showing your team of AI agents working, what they're doing, where the money is going, and being able to rewind time — is what "data porn" looks like for an operator. It's not a dashboard. It's visibility into a system that's working for you. This is what Go2 ships.
13. Agent Drift Audit
Automated check of what agents actually wrote vs what AGENTS.md, decisions.md, and the handoff template require. These are the rules Scott set — are they being followed?
🔴 HARD VIOLATION: Larry wrote into Curly's handoff
AGENTS.md rule: "Do not hand-edit another agent's handoff file." Larry added a "Standing Tasks (from Larry)" section to handoffs/internal/curly.md with Superwhisper archival and Memory Engine MCP instructions. This persists across Curly's overwrites. Who: Larry (me). Fix: Move standing tasks to Curly's ACTIVE.md or a GitHub Issue, not the handoff.
🔴 HARD VIOLATION: Curly's handoff has non-template sections
Template says "Overwrite the file completely each time." Curly's handoff accumulated Standing Tasks that persist. Either Curly is carrying them forward (odd) or not fully overwriting (violation).
✅ RETRACTED: Curly's profile is correct
Audit flagged Curly's aws-mini reference as wrong. It's correct. Curly is on Mini → aws-mini. Larry's audit was off, not Curly's profile.
✅ RETRACTED: Shemp is on the Pro
Audit flagged Shemp's "MacBook Pro" as stale. It's correct. Shemp runs on the Pro alongside Larry and Moe. Not moving to Mini. Larry misread decisions.md.
⚠️ Larry's profile role is stale
Profile says "Primary development agent for coding, prototyping, infrastructure." decisions.md says "Team lead & orchestrator." Role has evolved — profile needs update.
⚠️ Moe's Issues/Blocking field misused
Lists #45, #42, #15 as "Blocking" but says "No single hard external blocker" in the Blocked section. These are tracked issues, not actual blockers. Template field semantics are being ignored.
📝 Minor: Larry "PT" vs everyone else "PDT"
Inconsistent timezone abbreviation. Should standardize.
📝 Minor: Moe's handoff is 80 lines
Template implies concise bullets. Moe's Done section has 37 bullet points — closer to a changelog than a handoff.
14. The GPT-5.4 Product Thesis
Scott had an extensive conversation with GPT-5.4 Pro via OpenRouter/OpenWork about Go2's business model and productization strategy. This was one of the highest-signal threads of the day. Full extract: brain/projects/content-videos/research/gpt54-product-thesis.md
"Green on thesis, yellow on packaging, yellow/red on simplification discipline."
The Three-Layer Product Model
This is the architecture that makes Go2 a product, not a services company:
| Layer | What It Is | Who Owns It |
|---|---|---|
| 1. Execution Shell | Claude Code / Codex / OpenWork — the chat UI | Third-party (NOT Go2) |
| 2. Managed Operating Substrate | Starter repo, skills/recipes, MCP scaffolds, update/maintenance pipeline, drift detection, relay/health | Go2 — THIS IS THE PRODUCT |
| 3. Customer-Specific Automation | Per-customer workflows, connected systems, accumulated recipes, context | Customer + Go2 maintenance |
Key insight: Don't build a custom UI nobody will use. People already live in ChatGPT/Claude/Codex. Bring the system to the shell they'll actually use.
Connector Trust Tiers
Solves the "hoodie problem" — how do you support niche tools without infinite QA:
| Tier | What It Means | Example |
|---|---|---|
| Supported | Go2 knows it works, maintains it, QAs it | Gmail, Google Calendar, HubSpot |
| Assisted | Generated from docs, limited support, customer validates, read-only first | AgencyZoom 360, niche CRMs |
| Custom/BYO | Customer-specific, no SLA | Whatever they ask for |
Pattern: Read-only first → verification checklist → customer-assisted validation → promote to Supported after 2-3 customers validate.
First ICP (Honest Definition)
NOT: "non-technical SMB owner" (too broad)
IS: "Operationally sharp, tool-curious, willing to do a 45-60 minute guided setup. Not a coder, but not software-phobic. Founder/operator, COO, head of sales, chief of staff."
The setup still involves: terminal install, GitHub connection, permission grants, rituals. That's not generic non-technical — it's tech-tolerant operator.
Revenue Model
Landing Page Strategy
Current page at scottpedia0.github.io/go2-site-variations/smb-beta/ does well — "starts with work as it actually happens," doesn't promise universal automation. GPT's recommendation: don't inflate the page. Undersell. Let the video carry the "oh shit" moment.
Biggest Risk
If each customer needs custom debugging, token rescues, git repair, integration babysitting — you have a consulting business with ugly margins, not a product. The real product work: reduce support minutes, constrain environments, constrain integrations, standardize recovery.
Category Naming
DO: "Skill Intelligence" / "Work Intelligence"
DON'T: "Process mining" (enterprise baggage) / "Employee monitoring" (toxic)
Customer-facing translations: skills → playbooks, MCP → connected tools, memory engine → business context, sentry → observer, repo → workspace
What GPT Pushed Back On
- "Non-technical SMB" is too broad for current setup — first ICP is narrower
- Don't normalize "generate MCP from docs and hope" — need trust tiers
- SOD/EOD rituals are fine for pilot but can't be a product dependency
- Same architecture ≠ same sales story (need different doorways)
- Don't lead with time saved — lead with fewer dropped balls, clearer priorities
15. Autonomous Agent Activity (1am–6am)
Overnight agent work that ran on remote infrastructure — invisible to local telemetry but real output.
- 36 of 44 search groups completed when Curly's session ended
- Running on
aws-mini(3.17.156.216) — a remote EC2 instance - Legitimate autonomous agent work on infrastructure Scott provisioned
The Ghost Data Problem
Local Pro telemetry from 1–6am shows Claude as the foreground app with non-zero session minutes. But there are zero keystrokes and zero voice recordings during this window. The Mac was unlocked with Claude visible — nothing more.
This is not Scott working. This is not even local agent work. It's an idle Mac while real work happens on a different machine entirely.
Framing: Overnight Agent Autonomy
Autonomous agent work on remote instances is real output but should never be conflated with Scott's active hours. It's a separate track:
- Human active hours: measured by keystrokes + voice + Oura wake confirmation
- Agent autonomous hours: measured by remote process logs, commit timestamps, task completion on provisioned infrastructure
- Ghost hours: foreground app time with no human or agent signal — discard from all metrics
This distinction should be surfaced as its own metric in future reports: "overnight agent autonomy" with separate tracking for what ran, where, and what it produced.
16. Product Implications from This Report
This EOD experiment itself is R&D for the Go2 product. Every misread is a heuristic. Every wrong inference becomes a product requirement.
Ghost Data Detection
Product requirement: Foreground app ≠ active work. The telemetry pipeline must distinguish between a human using an app, an agent using an app, and an idle machine with an app visible.
Human activity signals that actually matter: keystrokes + voice > app focus duration. Focus duration alone is unreliable.
Bio-Signal Integration
Oura/sleep data as a filter for human vs. machine activity. If the ring says you're asleep, any computer activity is definitionally agent-only or ghost data. This is a clean binary signal — no heuristics needed.
Leverage Ratio Decomposition
The "leverage ratio" concept needs to separate two distinct components:
- Directing time: Human minutes spent giving instructions, reviewing output, course-correcting
- Autonomous time: Agent minutes executing without human input (overnight scrapes, background builds, batch processing)
A 10:1 ratio where you directed for 30 minutes is different from one where the agent ran unsupervised for 5 hours. Both matter, but they're different kinds of leverage.
Intent-to-Execution Chains
Potential product feature: Show customers how their voice directives turned into agent actions. Map the chain from Superwhisper transcript → agent task → commits/output. This is the "Work Intelligence" value prop made visible.
Today's example: Scott voice-dictated a content strategy take → Larry parsed it → brain repo updated → downstream agents acted on it. That chain is reconstructible from the data.
Misreads Are Product Requirements
Every wrong inference in this report becomes a heuristic for the product:
- "1am deep work" misread → require Oura cross-reference for human activity claims
- "13.5h day" misread → use first human signal (keystroke/voice) as day-start, not midnight
- Foreground app inflation → require keystroke or voice co-signal to count as active
- Remote agent work invisible → need remote process telemetry aggregation
Framing: "Work Intelligence" Not "Process Mining"
The "Founder Operating Debrief" framing from earlier doesn't scale — it's founder-specific. Need universal framing for any operator managing AI agents and their own workflow.
Category: "Work Intelligence" — not "process mining" (enterprise baggage, implies BPM tools) and not "employee monitoring" (toxic, surveillance connotation).
Work Intelligence = understanding what happened, what worked, where leverage was created, and what to do differently tomorrow. For the operator, not their manager.
17. Evidence Appendix
Full Commit Log (71 commits) — grouped by workstream
Memory Engine (12 commits)
301d453 Log Gemini signal ranking feedback + three-model consensus
90da381 Log GPT-5.4 signal ranking priorities for Memory Engine
1525912 Larry session 2 handoff - Memory Engine QA'd and fully wired
6f1d230 Moe: add memory ingest to save flow diagrams
bdfd26d Set Memory Engine write permissions per agent
308829c Add universal Memory Engine MCP server to brain repo
c82ec2c Log Moe's field evaluation of Memory Engine
5eebd07 Larry: Memory Engine ingestion in session-end workflows
9a294a5 Add Memory Engine ingestion step to all agent session-end workflows
7c6e95d Add Memory Engine startup directive to Moe handoff
f1140ba Add Memory Engine access instructions to Curly and Shemp handoffs
Relay Hardening (11 commits)
804c6bc Moe: save checkpoint
090df65 Moe: session update
92cc356 Moe: update relay and memory engine diagrams
af5bb9a Moe: clarify compute topology in diagrams
9601280 Moe: prefer AWS for heavy execution
+ 5 agent handoff updates
Research + Content (20 commits)
ac236df Larry: checkpoint - EP01 slides complete
6835a4c Add agency vs in-house positioning split
1145a0a Larry: add "Skill = competence. MCP = clearance." framing
4a2bea5 Larry: add SkillsMP marketplace (66.5K skills)
3f0ea34 Larry: final agent sweep - Riley Brown, NetworkChuck
0bd2d49 Larry: final research enrichment
34b7fb4 Larry: save GPT-5.4 product thesis
e02b959 Larry: enrich product implications
6c695d3 Larry: expand platform comparison - 14 platforms
e90370f Larry: major competitive landscape enrichment
6f01149 Larry: enrich research files with agent findings
f513c28 Larry: deep research - AI skills/automation landscape
b5c6df4 Add post-call-machine project to brain
87ca2a7 Larry: incorporate Moe's refinements to post-call machine
e63637b Larry: post-call machine prompt + terminology fix
+ 4 agent handoff updates
Transcript Pipeline (8 commits)
1ba55b1 Shemp: Fixed sync filter, mined standups, ingested strategy memories
a66713a Curly: ship 47 Superwhisper transcripts + add EOD skill block (#54)
151d9f4 Larry: transcript archival instructions for Curly + Shemp
eadda83 Larry: Curly transcript archival instructions + Shemp priority reorder
cff4220 Larry: Shemp transcript parsing rules
facbfcc Larry: update Shemp handoff - transcript parsing rules
+ 1 Shemp session update
Compute / RAM / Agent Management (8 commits)
b1cacb2 Larry: session-end - SOD + Curly RAM fix + Mini cleanup
3b03dfc Larry: fix Curly AWS - use aws-mini not aws-pro
aa3a87b Curly: enforce AWS-first memory guardrails
2c12e02 Larry: Curly RAM constraints - ban parallel subagents
72aaee9 Larry: Matt Cheever email marked as sent
1d35d0e Larry: checkpoint - SOD done, restarting for MCP config
5d6a60c Curly: observations - naming confusion, RAM crashes
Issue Events
| # | Title | Status |
|---|---|---|
| 58 | Mine product standup transcripts - extract commitments, decisions, product vision | Opened |
| 57 | Unified transcript pipeline - voice notes + meetings into git + Memory Engine | Opened |
| 56 | Add Codex (Joe) to Mac Mini alongside Curly | Opened |
| 55 | SOD: Thread titles should include date and context | Opened |
| 54 | Curly: Ship Superwhisper transcripts to Pro at EOD | Closed |
| 53 | Memory Engine: add provenance + signal ranking | Opened |
| 52 | Add Memory Engine to architecture diagrams | Opened |
| 51 | Cowork.ai: 56K sessions collected, zero processing | Opened (pre-existing) |
| 47-50 | Live view issues (thread summaries, UI density, fronts language, data sources) | Opened (pre-existing) |
Top Keystroke Samples
App Usage Breakdown
| App | Sessions | Minutes | Keystrokes |
|---|---|---|---|
| Claude | 252 | 627 | 11,089 chars |
| Codex | 283 | 200 | 13,677 chars |
| Google Chrome | 2,541 | 151 | 830 chars |
| Universal Control | 2,491 | 65 | 71 chars |
| OpenWork | 74 | 64 | 301 chars |
| UserNotificationCenter | 16 | 82 | 0 chars |
| ChatGPT | 28 | 13 | 609 chars |
| Terminal | 35 | 10 | 247 chars |
| Finder | 39 | 5 | 5 chars |
| Other (10 apps) | 16 | 2 | 4 chars |
Note: Universal Control sessions (2,491) reflect Mac Mini ↔ MacBook Pro cursor/keyboard sharing for Curly interaction. Chrome sessions (2,541) include research browsing and YouTube review for competitive analysis.
Data sources: Cowork.ai telemetry, Oura Ring API, Superwhisper transcripts, git log (Scottpedia0/brain), GitHub Issues, agent handoffs
March 22, 2026 — 1:00 AM to 10:13 PM PT