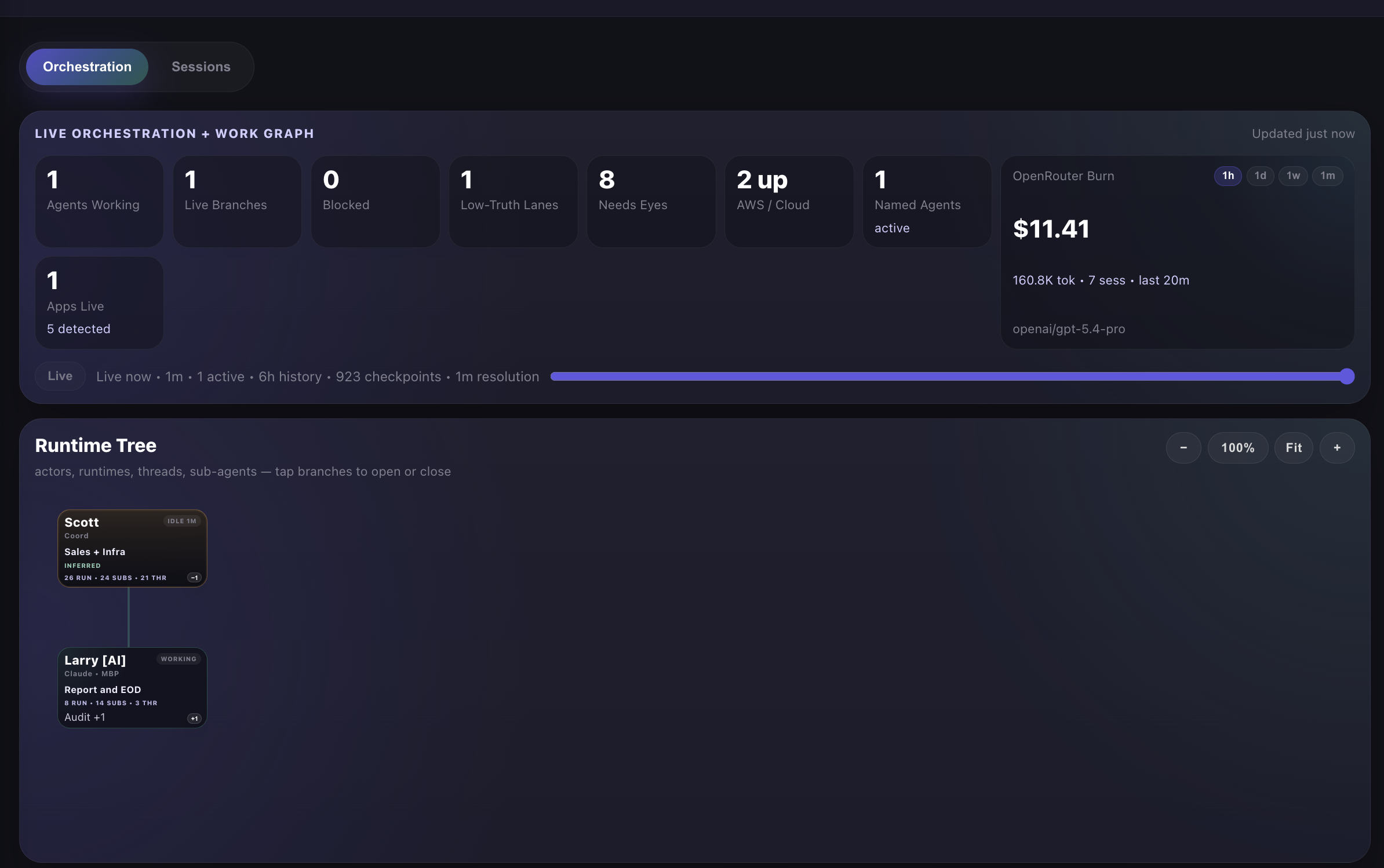
Scott Moran · founder individual audit · Mar 13-25, 2026
The machine compounds. The closure layer still breaks.
Most productive two-week stretch since late November. Best state was named build. Main failure was doing the work, building the machine, and still not forcing enough human closure.
This was the most productive two-week stretch since late November. Throughput, build-state frequency, and machine density all stepped up in the same window that the pilot page launched.
179 hours of dense work is performance, not a sustainability plan. The work got done. Recovery, sunlight, exercise, and genuine off-ramps still did not.
The product and company are already past built enough to sell hard right now. Building the brain was the right instinct. Another week of building it is mostly dressing.
You built the lead machine, the report machine, and the routing machine, then still ghosted live humans. That is a closure problem, not a capability problem.
You defined a new operating system for yourself faster than you defined one for the team around you. The machine compounds faster than the human governance layer does.
Questions Scott should answer
Why did the work get done but the send not happen? Where exactly did “almost ready” become a reason not to close, including the operator-partner reply and customer follow-up drafts that were already written?
If the system warned you to walk away, why didn’t you obey it? Alerts you override are theater until they change the machine.
If the most expensive frontier day created the most value per dollar, what is the repeatable recipe? Treat that day like a playbook, not trivia.
Some of your strongest days happened on poor sleep. Are you mistaking short-term voltage for a sustainable operating pattern?
If travel is unavoidable, how do you preserve the home-base conditions that produced this stretch? Keep PST, protect sleep, mirror diet, and stop letting hotel life rewrite the system.
This window produced real output, real leverage, and a very obvious closure problem.
These are the observations that should have been hard to miss inside the two weeks themselves.
They are here so the next window runs differently, not so the page can flatter the operator.
Positive
This was the strongest two-week run since late November.
Dense work, build-state frequency, orchestration depth, and the pilot launch all landed inside the same stretch. The machine did not just look busy. It actually moved.
Leak
You did the work and still ghosted the human loop.
Drafts existed. Reports existed. Routing existed. The missing move was still send, reply, decide, or follow up. The bottleneck is not technical. It is picking up the phone.
Leak
You built a self-governance system in the middle of go-to-market.
That instinct was right before the calendar turns into demos and calls. It is done now. The right next move is to use it, not keep rebuilding it.
Question
You defined a new OS for yourself. Why not for everyone around you?
Multiple agents and the team can already move with you. The governance layer still depends too much on Scott being the router, memory, and final convergence point.
Question
The system told you to stop. Why didn’t you listen?
Push notifications and tilt warnings only matter if they can interrupt the machine. Right now they mostly document the spiral after the fact.
Condition
Home-base stability mattered more than you usually admit.
Two weeks without travel or major interruption changed the floor of execution. If travel cannot be avoided, the operating environment has to be rebuilt on purpose: stay on PST, protect sleep, mirror diet, protect mornings, and stop letting hotels rewrite the system.
What to protect next window
Freeze the rubric in a repo file before agents start moving.
Keep named build days whole instead of letting them degrade into mixed-mode days.
Treat the high-spend, high-yield frontier day as a repeatable operating mode to document.
Route voice and meeting context into the shared brain the same day.
Replacing narrowing with more comparison, more routing, or a prettier surface.
Building the next layer of infrastructure instead of selling the machine that already exists.
Reopening work because a better articulation might exist somewhere in the machine.
Scorecard
Two-week findings and one-day examples are different kinds of evidence.
The scorecard up top should not blur the two together. This section makes the split explicit:
what only becomes true across the window, versus what one specific day made unusually legible.
Two-Week Finding
Build-state frequency improved more than closure did.
Across the window there were more real build days, more voice, and more AI handoffs than the prior period. That means the machine got more real. What did not improve proportionally was human-facing closure.
Two-Week Finding
Voice and orchestration increased, but the send layer stayed under-built.
The useful window-level read is not just “more agent activity.” It is that strategy capture and machine throughput rose while external follow-through lagged. That is why the report should emphasize closure and routing, not just capacity.
One-Day Example
1 : 6.4 was the first leverage metric worth keeping.
Mar 18-19 made the leverage concept visible. The original 1:45 number was wrong, but the corrected 1:6.4 was still a useful one-day example because it pointed the report toward leverage instead of raw activity.
One-Day Example
Mar 21 and Mar 24 made opposite truths easy to see.
Mar 21 showed the best-state build regime clearly. Mar 24 showed the opposite: 0 commitments cleared while queues kept growing. Those days are examples, not the whole finding. The finding is what repeated around them.
Window-level conclusions
Your best state is still a named build regime, not a mixed-mode day.
Rubric definition and preservation still determine whether agent speed compounds or turns to churn.
The machine is getting better faster than the human-facing close layer is getting tighter.
Use leverage, build-state frequency, and closure as the lead metrics. Everything else is secondary.
Single-day examples worth citing
Mar 18-19: leverage became measurable once voice + agent time were read together.
Mar 21: build-state got unusually clean and made the “named build regime” point obvious.
Mar 24: queue growth with 0 commitments cleared made the closure problem impossible to miss.
Mar 25: the stack was cleaner, but the human closure layer still lagged the machinery around it.
Operating Arc
The machine created leverage, then exposed exactly where it still leaked.
The point is not that every day looked the same. It is that the swing between the best day and the weakest day says exactly what needs fixing:
keep the build regime, preserve the rubric, and stop asking the human closure layer to improvise every night.
6.4x
Peak Leverage
Mar 18-19. Corrected leverage ratio once voice, multi-model orchestration, and machine time were read honestly.
0 cleared
Hard Dip
Mar 24. Queue growth outran send, follow-up, and same-day closure.
3 days
Build Streak
Mar 21-23. The machine stayed cleanest when the day had a named mode and fewer mixed surfaces.
4 + team
AI Team + Compute
Larry, Moe, Curly, Shemp plus the human team across MacBook Pro, Mac Mini, AWS offload, outbound, and live ops.
63 / 24 / 1
External Motion
63 deals wired, 24 warm emails queued, and a live booking inside the same two-week window.
Working Diagnosis
The limiting factor is closure under pressure.
Scott does not have an effort problem, an idea problem, or a willingness-to-build problem. The pattern is simpler:
when the evaluation rubric is clear, he moves fast, delegates aggressively, and gets high throughput from both himself and multiple agents.
When the rubric is incomplete or unstable, that same speed gets spent on comparison cycles, reopened decisions, and extra system-building that delays commitment.
The question is not whether Scott can do more. It is whether he can define the standard earlier, preserve it long enough to decide against it,
and route work through that standard without reopening the frame every time a new option appears.
If this report is useful, it should change behavior immediately. Freeze the rubric before exploration scales, separate architecture mode from execution mode, stop reopening work unless new evidence clearly beats the current path, and accept the obvious commercial read: Scott, the product and company are already past built, the machine runs at scale, sell hard while the window is open, everything else is more dressing.
Clickable System View
The leverage was not abstract. It came from a named stack with clear jobs, clear machines, and clear failure modes.
Click through the roles below. This is the part the report needed:
who was doing what, where the work actually ran, and where the stack was helping versus creating drag.
Founder / Router
Scott Moran
MacBook Pro · judgment + control
What Moved
Why It Mattered
Failure Mode
CEO Pressure Map
The public-safe version can still show where the real drag sits
The point here is not to flatten your work into generic productivity advice. It is to show the specific places a CEO-operator machine leaks:
meetings that should create leverage but create residue, follow-ups that get delayed while the scalable version gets prettier, strategy loops that stay wider than they should, and compute that is only partly disciplined.
Meeting Blindness
You were often showing up as the agenda, the memory, and the synthesis layer.
High-cost conversations were still too non-instrumented. When other people arrived underprepared, the CEO became the prep layer, the note-taker, and the post-call routing system by default.
Follow-Up Drag
The demos were not the bottleneck. The scale instinct fired before the thin bridge existed.
When a repeated manual gap appears, the founder tends to go build the missing function immediately. That instinct is product gold at scale, but in a crowded week it can outrun the thinner bridge that would have closed the live loop first.
Strategy Width
The stall is not thinking. It is leaving too many GTM doors emotionally open.
A bigger contract, a narrower pilot, a cleaner SMB story, a more bespoke enterprise story. The drag is not insight. The drag is narrowing even when multiple stories are clearly validated.
Promise Compression
The drag is not making promises. It is compressing too many of them into one mental queue.
Demos, recruiting, partner motion, investor follow-ups, and operator commitments were competing inside the same memory slot. Intent stayed high. Same-day retrieval and closure got more fragile than they should.
Machine Discipline
The three-machine setup is real leverage when routing stays honest
You already have a real control plane plus worker plane. The remaining leak is asking the local machine to hold heavy worker jobs, context, and CEO judgment at the same time.
How The Machine Actually Works
This laptop runs like an AI control room, with Chrome as the leak point.
App Stack
Most of the machine is three surfaces
By observed app time, the system is basically Claude, Chrome, and Codex.
Chrome matters because it hosts both leverage and drag: Slack, Meet, Google surfaces, GitHub, websites, and random admin gravity.
Claude
56.6h
Chrome
49.8h
Codex
28.0h
OpenWork
2.5h
ChatGPT
2.1h
Terminal
1.9h
Inside Chrome: 10.3h Slack, 10.2h Google Meet, 6.7h Google surfaces, 1.8h GitHub, 1.55h larry.moran.bot.
Chrome is not “wasted time.” It is where too many different jobs are sharing the same window.
Clock Signature
This is operator-time, not office-time
Your keyboard pattern backs the older read almost perfectly: morning is not the main event.
Evening and late night carried about 76% of all typed output in the window.
Morning
28,928
Afternoon
25,063
Evening
91,120
Late Night
77,789
Meaning. If you judge yourself by a fake morning-maker standard,
you will misread your actual machine and create shame that the data does not support.
Day-By-Day
Mode mix across the instrumented days
The pattern is obvious. March 19, 21, 22, and 23 were build-heavy runs.
March 18 got swallowed by meetings. March 24 and 25 show the admin leak vividly.
BuildMeetingsAdmin / commsOther
Mar 13
1.0h · 1,115 chars · 1 handoff
Mar 17
14.3h · 20,587 chars · 210 handoffs
Mar 18
22.6h · 26,766 chars · 210 handoffs
Mar 19
24.0h · 43,166 chars · 428 handoffs
Mar 20
23.6h · 30,905 chars · 330 handoffs
Mar 21
10.3h · 28,798 chars · 376 handoffs
Mar 22
23.4h · 23,058 chars · 316 handoffs
Mar 23
12.1h · 8,801 chars · 539 handoffs
Mar 24
16.3h · 23,475 chars · 615 handoffs
Mar 25
10.7h · 16,229 chars · 278 handoffs
Context Layer
The machine only makes sense when compute, body-state, voice, and memory are read together.
The older EOD lane made this much clearer than the early draft here: voice carried founder intent, telemetry carried behavior,
and the shared brain plus memory layer existed so every model did not start from zero.
Compute Topology
Which machines are doing what, and where the leverage changed
The clean operating pattern is local machine for control and context, AWS for worker fan-out and heavy runs.
The reports are explicit that the Mini was getting under-leveraged as a control plane and over-leveraged as a local worker box until the AWS-first correction landed.
MacBook Pro: control room for Larry, Moe, context, live relays, direct build, and decision-making.
Mac Mini: bulk scrape, enrichment, sentry, and remote-worker orchestration through Curly.
AWS Pro: overflow CPU/RAM for browser runs, helper workers, heavy parallel jobs, and model dispatch.
Real correction made in the window. Curly was crashing the Mini by using local parallel subagents instead of AWS.
The fix was explicit: AWS-first guidance, RAM guardrails, and local surface cleanup.
Body Signal
Oura is useful here as a truth filter, not a wellness widget
The strongest sleep insight is not generic “sleep matters.” It is that Oura helps separate human work from overnight agent/background activity,
and REM trend looks like an early warning light for cognitive fragmentation.
Sleep 88: the doctrine/build day that hardened Relay, compute, and Memory Engine guardrails also logged a long, high-output work stretch.
15-day trend: average sleep score 67, with crashes at 37 and 38. REM moved with the crashes.
Usefulness: Oura gives a hard human-vs-agent filter and a better way to read late-night output without lying to yourself about what was you versus what was the system.
Why this matters. Low REM is not a moral failing. It is a real cost signal.
Good sleep seems to buy doctrine/build days. Bad REM seems to buy fragmentation that you then try to outrun.
Sleep / Output Read
Selected body-state reads from the daily reports
This is not a finished statistical model. It is the clearest public-safe read from the daily reports:
body-state changes what kind of work compounds, and Oura keeps the story honest about what was human work versus agent/background activity.
Sleep 88
Doctrine / build day
Sleep 73
Mixed ops + investor prep
Crash 37/38
Fragmentation warning
The useful read is not “sleep score equals productivity.” It is “body-state changes whether widening compounds or backfires.”
Voice / Intent Layer
Telemetry without context lies. Voice is the missing intent layer.
One of the strongest EOD lessons was that app telemetry alone can misclassify the work. The voice layer showed what the machine was actually for:
architecture framing, GTM narrowing, delegation, correction, and founder intent routing.
Superwhisper: voice was being used for rapid direction-setting, not just dictation.
Leverage ratio: voice carried the strategy brief while keystrokes and agents carried tactical correction and execution.
Implication: without transcripts, a report can mistake sales work for coding, meetings for dead time, and orchestration for drift.
Product thesis from the EOD lane. Telemetry without context lies. Voice is what turned raw activity into attributable intent.
Shared Context Layer
The shared brain and Pinecone memory layer were built to kill reshare tax
The point was not “save notes somewhere.” The point was to make decisions, transcripts, rubrics, and operating context reusable across Claude,
Codex, OpenWork, and future agents without briefing every model from scratch.
Brain repo: decisions, rituals, architecture, handoffs, and project state became the durable substrate.
Pinecone memory layer: retrieval moved from “hope the model remembers” to explicit cross-session, cross-model recall.
Transcript ingestion: Superwhisper and meeting transcripts stopped being dead artifacts and became searchable context.
Why it matters. This is the fix for context transfer drag. The win is not better note-taking. The win is not having to reshare the same founder context to every model all day.
What Actually Happened
The window did not just produce analysis. Specific lanes moved.
This matters because your strongest pattern is leverage through orchestration, not solo typing.
The report would be lying if it acted like only direct keyboard output counts as real work.
March 24-25
Four real deliverables were redacted hard enough to become reusable examples
This was not one lane. Multiple existing deliverables were cleaned, redacted, and made safe enough to reuse as product evidence without leaking customer internals.
March 22-23
The SMB page got concrete enough to use as a working example, not just talk about
The offer, install framing, and evidence got sharpened into something concrete enough to click through. The work moved from “we should package this” toward an actual page with actual receipts.
March 22-24
Transcript mining turned into a review-and-routing machine
Hundreds of Zoom transcripts were processed for pain points, objections, next steps, and fit. A hosted review/send surface plus direct-draft workflow let those outputs queue for a review owner instead of dying in notes or chat.
March 23
The remote worker factory proved the compute split was real
A documented 7-stage enrichment pipeline on aws-mini produced 988 outreach-ready contacts and staged HubSpot test deals. The bigger point is that worker labor had left the founder laptop and started behaving like scalable infrastructure.
March 24
A real time-tracking outage became an operator and infrastructure test
The system absorbed a production outage affecting 200+ workers, patched the stack, upgraded the VM, added healthchecks, and turned a painful incident into concrete reliability lessons.
March 19-24
The founder promise stack stopped being purely ad hoc
A repeatable lane got formalized: transcribed call to structured summary to draft to review/send to pending reply. That matters because the CEO promise stack can no longer live only in memory.
March 22-24
Voice notes stopped dying in a folder and started becoming reusable context
Historical and new Superwhisper transcripts were shipped, ingested, and made queryable as working artifacts. The point was not archiving for nostalgia. It was making founder intent reusable across models.
March 20-23
The shared brain plus Pinecone memory layer became real operating substrate
Decisions, rituals, project state, and transcript-derived context moved into a shared brain with a retrieval layer. That changed memory from “hope the chat still has it” into explicit cross-session infrastructure.
March 22-25
Layout hardening and individual spec writing made the discovery page usable
Table cleanup, spec-writing, and clearer role-shaped installs turned rough internal material into something legible without flattening the underlying story.
Evidence
Open the underlying diagrams, diagnostics, and pages directly
These artifacts matter because they were written during the window itself, not retro-built to make the page look more serious.
The cards below are meant to be opened immediately.
Separate architecture lane. In the same discovery window the shared brain logged 336 repo/documentation moves and 45 touches to diagrams, current-state architecture,
or the decision log. The diagrams, decision pages, and current-state docs were being maintained as their own operating stream while the work was happening. This report is the synthesis layer sitting on top of that lane, not the first place those changes were written down.
Why that matters. Anyone clicking through should find a real paper trail: compute-topology updates, memory/relay changes,
naming and terminology decisions, ritual changes, and architecture diagrams that moved during the same two-week window as the operator discovery itself.
These are the short-run recipes that turn your best patterns into defaults and stop the worst ones from disguising themselves as strategy.
They are meant to be stolen, installed, and tested quickly.
CEO Build Day
Name the mode early and protect it like a production dependency
Use when: a build or doctrine day matters more than inbox gravity.
Recipe: Claude, Codex, Terminal, and one active repo first. No Slack, Meet, webmaster, or search until an artifact exists.
Install: Build-mode launcher plus separate admin sweep.
Why it works: your best days are named build days, not mixed-mode marathons.
Low-REM Day
Use Oura as a widening gate, not a guilt meter
Use when: REM slides or readiness craters.
Recipe: no new GTM story, no new infra lane, no strategic widening. Route the day toward closure, grading, queue review, and smaller irreversible wins.
Install: Oura gate plus closure sweep.
Why it works: low REM seems to buy fragmentation that you then try to outrun by opening more loops.
Post-Demo Day
Use a thin bridge before building the whole missing machine
Use when: a demo, discovery call, or investor call ended with a real promise.
Recipe: transcript to pain extraction to draft to review/send on the same day. If the full platform function is not ready, use the thinnest script or manual bridge that still closes the live loop.
Install: promise tracker, thin send-bridge, then transcript-to-review queue.
Why it works: your instinct is to solve the root scale problem immediately. That is usually right in the long run and sometimes too expensive in the middle of a crowded week.
Heavy Meeting Day
More meetings can be correct for a CEO. More unprepared meetings never is.
Use when: the day is mostly calls, coordination, or deal motion.
Recipe: agenda request 24h and 30m before, auto-cancel if materials are missing, then decisions and owners get written down without relying on memory.
Install: meeting brief, cancellation enforcement, and post-call capture.
Why it works: meeting leverage is probably under-instrumented, not overused.
Promise Stack Day
Name every promise object before improving the machine around it
Use when: calls, demos, recruiting, or partner motion create more follow-up than one brain should carry.
Recipe: every promise gets an owner, due date, bridge action, and escalation path the same day. Same-day send outranks making the reusable system prettier.
Install: promise tracker, daily escalation rail, and thin send-bridge.
Why it works: trust decays faster than the machine improves. Protect the live edge first and harden the pattern second.
Operating Rules
The gate logic belongs here because it changes what kind of day is allowed to happen
These are the rules I would actually enforce because they shut down the repeat failure modes without flattening how you think.
The first three are body-state gates. The rest are business-state gates.
Green Day
Widen, build, decide
Good readiness and stable sleep mean the machine can support doctrine work, sharper decisions, deeper build blocks, and harder narrowing.
Yellow Day
Refine, grade, route
If the body is middling, do not spend the day inventing new strategic branches. Use the day for review, dispatch, cleanup, and lighter-weight closure.
Red Day
Close loops only
If REM and readiness are clearly off, the day becomes a close, grade, review/send, and prep day. No widening, no elegant new infrastructure lane, no fake heroics.
Meeting Gate
No agenda, no live meeting
If required inputs are missing by T-30, downgrade async or reschedule. The CEO should not be the silent buffer for everyone else’s prep debt.
Follow-Up Gate
Promises from calls must hit a queue the same day
If a call generated a real promise, that promise enters review/send and pending replies before the day ends, even if the reusable system is still getting better.
Cloud Routing Gate
Worker jobs do not belong on the judgment machine
Scrapes, browser farms, enrichments, and bulk transforms go to AWS by default once they stop being tiny. Keep the local box for taste, routing, and live control.
Automation Recommendations
The installs I would actually queue, in order
These are the public-safe versions of what the internal report points toward. They are specific enough to feel real and generic enough to avoid leaking the best internals.
Queue this like software, not strategy. If this were the live Monday install order, I would queue
founder-intent-router, promise-tracker, and meeting-control first, then add
transcript-to-action, compute routing, and rubric memory once the approval inbox exists.
The point is a visible queue, a few background sentries, and an operator surface another founder can actually imagine installing.
1. Promise Tracker
Turn every founder promise into a tracked object
Transcript or meeting note becomes promise, owner, due date, draft, and reminder. Nothing important dies in memory or in chat residue.
Queue nowNeeds transcripts + tasksReview required
Prevents
Delayed replies after good calls, especially when platform work feels more urgent than sending.
2. Meeting Brief + Cancellation Daemon
Make the calendar earn its keep
Auto-brief strategic calls, collect agenda items, chase missing prep, and cancel or reschedule when the inputs never arrive.
Queue nowNeeds calendar + docsRuns in background
Prevents
CEO time turning into meeting prep subsidy for the rest of the room.
3. Transcript-To-Action Queue
Convert calls into queued action, not better notes
Pain points, decisions, next steps, and fit get extracted automatically. Strong calls queue follow-up drafts, issue objects, or pilot actions for operator or review-owner approval.
Queue nextNeeds transcript intakeApproval inbox
Prevents
Good customer, partner, recruiting, or investor conversations vanishing into transcript folders.
4. Compute Router
Auto-route the heavy jobs to the right machine
The local machine stays the control plane; AWS handles the long-running workers, scrapes, and browser tasks without requiring manual babysitting.
Queue nextNeeds cloud worker railInvisible to operator
Prevents
Local RAM starvation, context loss, and noisy confusion about what belongs where.
5. Founder Intent Router
Route voice and fresh context once, then share it everywhere
Whisper/Superwhisper and meeting transcripts become one classified context stream that feeds the shared brain, the right model, and the right queue without repeated manual re-briefing.
Queue nowNeeds voice + memoryHigh trust value
Prevents
Human API-router behavior, context shuttle tax, and the same founder brief being pasted into every model by hand.
6. Rubric Memory Layer
Capture “why this is better” the moment it appears
When you reject or prefer an output, the reasoning becomes a reusable brief, exemplar, or scoring rule instead of disappearing into one conversation.
Queue nextNeeds git + memoryCompounds taste
Prevents
Compare-edit churn across shells and repeated re-explanation of taste.
7. Role Kernels
Package the same substrate differently by role
Operator, sales, support, and lead-gen each get their own review queue, approval layer, and recommended playbooks instead of one vague “assistant.”
Selling abstraction when the real need is relief from a repeated loop.
Prescriptions
What to change in the founder operating system, and what the company should standardize around it
The point of a report like this is not just diagnosis. It is to convert observation into a tighter operating system for the person
and a more repeatable working approach for the company.
Founder-Level Changes
What you should do differently
Run single-mode starts. Decide whether the first serious block is build, sell, or operate. Do not let Chrome mix all three before an artifact exists.
Use body data as a scope signal. When sleep or readiness crashes, do not widen. Route that day toward closure, grading, delegation, and smaller irreversible wins.
Capture the rubric at first irritation. The moment you say “that is not quite it” or “this is better,” turn the judgment into a reusable rubric in git that same day.
Send the promised follow-up before polishing the reusable version. The first recipient should not wait for the template to get perfect.
Bias the calendar toward leveraged meetings, then instrument them hard. As CEO you probably should be on more decisive calls, but fewer vague ones and zero underprepared ones.
Keep the compute split honest. Use the local boxes for control, taste, and context. Push browser automation, enrichment, and bulk transformation to AWS by default.
Pair every new system lane with external closure. Before opening the next infra, GTM, or product thread, force one send, one ask, one decision, or one closed loop outside the machine.
Company-Level Changes
What Go2 should standardize
Productize the review/send machine. Transcript ingestion, pain extraction, draft generation, approval, and CRM update should be a maintained company lane, not a one-off internal trick.
Standardize role kernels. Build repeatable flows for operator, support copy-paste, sales follow-up, lead-gen ops, and meeting hygiene instead of one giant vague “AI assistant.”
Design for passive capture, not perfect rituals. The system should create value from transcripts, clipboard patterns, task flow, and app telemetry even when humans skip the ceremony.
Create explicit trust tiers. Let teams see the ladder from observe to draft to queue to execute so adoption does not depend on blind trust in automation.
Harden the worker substrate. Health checks, restart logic, and failure visibility are not side quests. The outage week proved they are product credibility.
Keep it concrete. The useful story is fewer dropped follow-ups, fewer wasted meetings, less copy-paste, and better prepared people, not vague intelligence claims.
Skills + MCPs + Sentries
The install should feel real, not just described
A plain-language trigger is useful, but it undersells the real system. The real install surface is:
a skill that tells the agent what to do, the MCPs that give it access,
a sentry or daemon that watches for drift, and a small script/spec that makes the whole thing feel real.
Build these MCPs first. Calendar + meeting context, Superwhisper and meeting transcript intake, CRM + Gmail, memory/brain search + vector memory, Oura, GitHub + Sentry + cloud logs, and a review queue/approval surface.
That set covers most of the leverage in this report without giving away the private substrate.
What lands on the machine
A small local inbox with queued installs
An approval surface for drafts and actions
Hidden context sync from voice, meetings, and memory
What runs in the background
Meeting-readiness sentry
Promise-lag sentry
Context-drift sentry
What it plugs into
Calendar
Transcripts
Gmail / CRM / memory
meeting-control
Skill + MCP
Turns live meetings into a controlled loop: pre-read, agenda chase, post-call decisions, and follow-up routing.
Skill:meeting-control
MCPs: calendar, meeting transcript source, memory/brain search, team chat or tasks
Sentry:meeting-readiness-sentry watches for missing agenda, missing pre-read, and missing post-call decisions
{
"skill": "meeting-control",
"trigger": "calendar.event.upcoming",
"required_mcps": ["calendar", "transcripts", "memory", "tasks"],
"sentry": "meeting-readiness-sentry",
"rules": {
"t_minus_24h": "request agenda and required inputs",
"t_minus_30m": "escalate if materials missing",
"t_minus_10m": "draft reschedule if still unprepared",
"post_meeting": "extract decisions, owners, deadlines, resume brief"
}
}
post-call-followup
Promise Stack
Converts important calls into a real review/send queue instead of leaving the promise stack in memory.
Sentry:promise-lag-sentry flags calls with explicit promises that still have no draft or send action by end of day
{
"skill": "post-call-followup",
"trigger": "transcript.created",
"required_mcps": ["transcripts", "crm", "gmail", "review_queue", "memory"],
"sentry": "promise-lag-sentry",
"extract": ["pain_points", "objections", "buying_signals", "next_steps", "explicit_promises"],
"actions": [
"score fit and urgency",
"draft follow-up",
"queue for review",
"update deal record",
"alert if no send path exists by end of day"
]
}
incident-hotfix-watchdog.py
Infra Sentry
If a code-based problem needs a quick fix, this is the kind of sentry that should already be running: unresolved errors, healthcheck status, and issue creation in one loop.
Skill:incident-hotfix
MCPs: GitHub, Sentry, cloud logs or healthcheck endpoint, deploy rail or shell access
Sentry:incident-hotfix-sentry watches error spikes, failed healthchecks, and missing owner assignment
#!/usr/bin/env python3
import os, requests, subprocess, sys
SENTRY_ORG = os.environ["SENTRY_ORG"]
SENTRY_PROJECT = os.environ["SENTRY_PROJECT"]
SENTRY_TOKEN = os.environ["SENTRY_TOKEN"]
HEALTHCHECK_URL = os.environ["HEALTHCHECK_URL"]
GITHUB_REPO = os.environ["GITHUB_REPO"]
headers = {"Authorization": f"Bearer {SENTRY_TOKEN}"}
sentry_url = (
f"https://sentry.io/api/0/projects/{SENTRY_ORG}/{SENTRY_PROJECT}/issues/"
"?is=unresolved&sort=date&statsPeriod=1h"
)
health_ok = requests.get(HEALTHCHECK_URL, timeout=10).ok
issues = requests.get(sentry_url, headers=headers, timeout=15).json()
hot = [i for i in issues if i.get("count") and int(i["count"]) > 10]
if (not health_ok) or hot:
title = "Hotfix watch: healthcheck failed or Sentry spike detected"
body = f"health_ok={health_ok}\\nopen_hot_issues={len(hot)}"
subprocess.run(
["gh", "issue", "create", "--repo", GITHUB_REPO, "--title", title, "--body", body],
check=False,
)
print(body)
else:
print("hotfix watch clear")
founder-intent-router
Context Layer
Turns Superwhisper and meeting transcripts into classified, searchable context so founder intent survives across models and sessions.
Sentry:context-drift-sentry flags repeated manual re-explanations of the same context or missing transcript syncs
{
"skill": "founder-intent-router",
"trigger": "transcript.created",
"required_mcps": ["superwhisper", "memory", "vector_memory", "decisions"],
"sentry": "context-drift-sentry",
"classify": ["decision", "question", "brainstorm", "delegation", "status_update"],
"actions": [
"write founder-intent brief",
"store searchable summary in brain",
"embed into Pinecone or vector layer",
"link to active project or decision log",
"surface relevant context on next model session"
]
}
support-approval-kernel
Support
This is the install behind the “copy-paste grinder” role: cluster repeat requests, draft replies, approve fast, and catch policy drift.
Skill:support-approval-kernel
MCPs: help desk, knowledge base, review queue, metrics surface
Sentry:policy-drift-sentry flags answers that fall outside accepted templates or performance thresholds
{
"skill": "support-approval-kernel",
"trigger": "ticket.message.created",
"required_mcps": ["helpdesk", "knowledge_base", "review_queue", "metrics"],
"sentry": "policy-drift-sentry",
"loop": [
"cluster repeated issues",
"draft response from approved sources",
"approve/edit/skip in one surface",
"promote accepted replies into templates"
]
}
Plain-Language Playbooks
Human-readable prompts after the skill and MCP layer exists
This is the operator-friendly layer the report should make obvious immediately.
The section above shows the actual install surface. This section shows the plain-English version of how those installs would behave day to day.
Meeting Prep Enforcement
Operator
Useful when people keep showing up without agenda items and you end up carrying the prep burden.
Before every scheduled meeting, remind agenda owners 24h before and 30m before start.
If required inputs are still missing 10 minutes before the call, draft a reschedule note and suggest moving the meeting.
After the meeting, extract decisions, owners, and follow-ups and route them into the right repo, issue, or CRM record.
Build Mode Launcher
Operator
Useful when Chrome keeps swallowing the first serious block of the day before build momentum lands.
When I say "start build mode," open Claude, Codex, Terminal, and the active repo.
Mute Slack notifications for 90 minutes.
Block Google Meet, app.slack.com, search, and webmaster surfaces until the block ends.
At the end of the block, ask me for one durable brief or shipped artifact.
Rubric Lock
CEO
Useful when interesting new framings keep reopening work that should already be in execution mode.
Before starting a new initiative, force a written rubric: objective, success criteria, hard constraints, kill conditions, and what will be ignored.
Write that rubric to the active repo, decision log, or project brief before agents start moving.
Once execution begins, do not reopen the rubric unless new evidence clearly beats the current path against the existing standard.
If a better idea appears mid-flight, tag it for V2 and keep shipping the current decision.
Transcript-To-Action Queue
Operator / GTM
Useful when important calls create real insight, but follow-up, prioritization, and system routing lag behind.
When a discovery, customer, partner, recruiting, or investor transcript lands, extract pains, decisions, buying signals, next steps, and stakeholders.
Score whether the call showed urgent pain, a real promise, or a clear action path for the current pilot or offer.
If yes, draft the follow-up in the assigned sender's voice, queue it in the review surface, and update the relevant record.
If no, mark it low-priority and keep the transcript searchable for later pattern mining.
Oura Gate
CEO
Useful when the machine keeps trying to widen strategy on a day your body is clearly asking for narrower work.
When today's Oura readiness is low or REM has been falling for 2+ nights, mark the day as a narrow day.
Do not open new GTM, product, or infrastructure lanes.
Prioritize closure, review/send, meeting prep, and grading existing work instead.
If I try to widen anyway, remind me this is a low-REM day and ask what outward loop gets closed first.
Promise Tracker
CEO
Useful when good calls turn into “I owe them something real” and then get outrun by system-building.
After every demo, discovery call, or investor call, extract every explicit promise I made.
Create one tracked item per promise with owner, due date, source transcript, and suggested next step.
If no draft or send action exists by end of day, queue a follow-up draft automatically and remind me before I start a new build lane.
Support Copy-Paste Grinder
Support
Useful for the kind of role that spends hours copying comments or questions into AI and then manually approving the result.
If a support agent pastes the same kind of issue into AI over and over, log the repeated prompts, cluster the common request types, and generate a reply draft with an approval UI.
Approve, edit, or skip with one click.
Turn accepted replies into reusable templates over time.
Remote Worker Factory
Worker Infra
Useful when the local machine is trying to be both the control plane and the worker box.
Use local machine for control and context only.
Push scrape, enrich, verify, browser automation, and bulk transformation work to AWS workers.
Return staged CSVs, CRM-ready rows, and a short operator brief when the run finishes.
Voice-To-Intent Bridge
Operator
Useful when your strategy lives in voice notes but the working shell only sees the last prompt you typed.
When Claude Code or Terminal opens, inject the last three voice notes plus today's top open loops from the shared brain and vector memory as hidden context.
Summarize the strategic intent in 5 bullets before taking the next action.
Write any new decisions back to the brain so the next model session does not need the same re-brief.
If the new task conflicts with the last voiced priority, ask for confirmation first.
Core Findings
What to keep, what to fix, and what keeps reopening the same loop
1. You work like an AI team manager.High confidence
What we saw. 56.6 hours in Claude, 28.0 in Codex, 2,805 AI handoffs, and roughly three quarters of all typed output landing in Claude and Codex. You are not using models as toys. You are using them as thinking surfaces, delegation surfaces, and comparison surfaces.
Why it matters. This is a strength. It is also why orchestration can feel productive even when the real bottleneck is choosing and committing. The system should optimize for routing, convergence, and durable artifacts, not a fake “single maker” ideal.
2. Your best state is a named build regime.High confidence
What we saw. The best days in the window are the build-heavy ones: March 19, 21, 22, and 23. The uglier days are not low-effort days; they are mixed-mode days where Slack, search, meetings, websites, and build all share the same surface.
Why it matters. Open-ended mixed-mode days are not neutral for you. They are hostile. The right unit of analysis is not total hours. It is whether the day stayed true to its intended mode.
3. Rubric capture is the missing layer underneath all the AI leverage.High confidence
What we saw. The strongest read across the prior reports still holds: once you know what “good” looks like, you can use AI extremely well. When the criteria are fuzzy, time gets burned across multiple models, tabs, and drafts.
Why it matters. You are not bottlenecked by idea generation. You are bottlenecked by defining and preserving evaluation criteria. That is why rubric capture and reuse deserves to be a first-class layer in your system.
4. You are so interruption-elastic that you can underprice switching.High confidence
What we saw. The psych profile was right: you can bounce out, collect signal, and snap back quickly. That resilience is real. But it also means you can underestimate how much mode churn is happening because the re-entry path feels cheap.
Why it matters. Recovering fast is not the same as switching for free. This is why days can feel productive and still leave you with less actual closure than they should.
5. Closure debt is real, and under pressure it looks like more motion.High confidence
What we saw. Mar 24 made it legible: 0 commitments cleared while the queue still held 988 contacts, 112 approved Katie emails, 15 Engage analyses, and multiple live follow-ups waiting. The work did not stop. The send layer did.
Why it matters. This is not laziness. It is a pressure-to-motion converter. Stress becomes throughput, and throughput becomes camouflage for unresolved commitments.
6. Context fidelity is a real operating requirement for you.High confidence
What we saw. The sharp frustration pattern in the reports is consistent: wrong dates, memory drift, fake completion, or tools acting more capable than they are. When context trust breaks, you reopen manual control loops yourself.
Why it matters. For you, broken memory is not a minor UX annoyance. It is an adoption blocker. Any automation that cannot preserve context fidelity will get demoted no matter how flashy it looks.
7. System-building can become safer than the human loop.Hot risk
What we saw. One of the harder truths from the deeper reports is that building systems can become emotionally safer than sending the follow-up, forcing the decision, or narrowing to one GTM story.
Why it matters. This is where more infrastructure can quietly become elegant deferral. The fix is not “stop building systems.” The fix is to pair new system work with mandatory external closure and admit that the product is already real enough to sell hard now.
8. CEO meeting load is not the problem. Unprepared meetings are.Meaningful
What we saw. Meetings already occupy real time in the window, and the meeting-content gap in the reports suggests you are losing leverage twice: once in the call, then again because decisions and prep context are not being carried cleanly.
Why it matters. A CEO probably should be on more decisive calls, not fewer. The fix is to make the calendar enforce agenda quality, pre-reads, and post-call capture so meetings become leverage instead of residue.
9. You attack missing scale functions early, which is product strength and weekly drag at the same time.Hot risk
What we saw. When a manual gap appears, you tend to spot the underlying missing function quickly and go build toward the scalable version: transcript mining, review/send, routing, better structure, better installs. That is not the product failing. That is you refusing to keep paying the same manual tax.
Why it matters. This is one of the cleanest CEO-specific tensions in the set. You do not need less machinery. You need a rule that says some weeks deserve the thin bridge, small script, or tolerated manual path first, and the deeper machine second.
10. The system can warn you, but right now it cannot govern you.Meaningful
What we saw. The corpus flags stop / tilt notifications, forgotten done and psst commands, and noise-heavy interruption patterns like 390 Slack sessions in 34.4 minutes on Mar 19. The system is seeing the problem. It is not interrupting it.
Why it matters. Alerts you ignore are documentation, not control. If the machine says walk away and nothing changes, the governor is fake.
11. Home stability was part of the result, not background noise.Meaningful
What we saw. This was the first sustained home-base stretch in a long time, and the stability shows up in the throughput. Travel and court logistics were already bending planning around Manila by the end of the window, while other reports still had ghost-hour problems where the machine was on and nobody was home.
Why it matters. If travel cannot be avoided, the answer is not pretending the environment does not matter. Stay anchored to PST, book flights around sleep, mirror diet, use light aggressively, and stop letting a hotel become a new operating system.
12. One side cashflow experiment got worse when complexity went up.Meaningful
What we saw. A parallel cashflow experiment produced steadier returns at the simpler tier than after the machine moved up in complexity. More sophistication did not create more value.
Why it matters. Revert to the proven tier, duplicate it on another box if it still matters, and stop spending founder attention improving a system whose marginal return already collapsed.
Strengths To Lean On
What to keep using hard
Fan-out, compare, and converge. That is a real superpower when the rubric is explicit.
Using yourself as the first hard customer. It keeps the product honest.
Turning internal pain into real tools and working surfaces fast once the pattern is clear.
Working in the afternoon, evening, and late night when the machine actually has voltage.
Demanding accuracy and context fidelity instead of accepting fake completion.
Failure Modes To Stop Rationalizing
What to stop excusing
Mixed-mode days as the default operating pattern.
Letting valuable context live only in handoffs instead of canonical files.
Treating meetings as expensive time but not instrumenting their decisions, owners, and prep quality.
Opening more lanes when narrowing feels painful.
Treating every missing function like it must become a full machine immediately, even when a thinner bridge would close the live loop this week.
Letting system-building count as closure when the real move is send, ask, decide, or ship.
Next 14 Days
What to do in the next 14 days if this report is supposed to help
First 3 installs on Monday.rubric-lock first, founder-intent-router second, and meeting-control third.
That stack attacks criteria drift, the context-resend tax, and the meeting-prep subsidy before anything more elegant gets built.
Days 1-2
Freeze the decision surface
Capture five recurring rubrics in git, not in memory.
Set a rubric-lock point for the active pilot lane.
Split compare mode from execute mode so Chrome stops acting like both workshop and junk drawer.
Days 3-7
Install same-day closure rails
Turn meeting prep into enforcement instead of hope.
Force same-day promise capture after every real call.
Use the Oura widening gate so low-REM days narrow and close instead of pretending to be strategic.
Days 8-14
Make leverage measurable and harder to fake
Tag every reopened loop as missing rubric, changing rubric, unclear owner, or weak threshold.
Pair every new system lane with one external closure: send, ask, decision, or ship.
Keep heavy worker jobs off the judgment machine so the control plane stays clean.
Compared With The Prior Two Weeks
Directional comparison, not a compliance ledger
Modeled public-safe composite
This is the comparison layer the report was missing. The point is not fake precision. The point is seeing what direction the operating system moved and where it still failed to create real closure.
Signal
Prior 2 Weeks
This Window
Read
Keystrokes
~276k
~223k
Down. Less brute-force typing, more orchestration.
Voice captures
~730
1,764
Way up. Strategy moved harder into the voice and transcript layer.
AI handoffs
~1,480
2,805
Up sharply. The machine got more real.
Named build days
1
4
Up. Best-state operating pattern showed up more often.
Human-facing closes
~12
~13
Almost flat. The machine improved faster than closure did.
What success should look like by day 14
Five reusable rubrics live in git and get reused by agents.
Every important call yields a same-day follow-up object and visible next step.
Meetings without agenda or pre-read stop making it to the live calendar.
At least one active GTM or product lane gets narrowed instead of endlessly improved.
The local box is spending more time on judgment and less on worker thrash.
What not to do next
Do not open a fresh strategic branch on a bad-body-state day.
Do not build another beautiful subsystem before one external loop gets closed.
Do not reopen the frame just because a cleaner articulation exists.
Do not let strong calls sit overnight without a draft, owner, or due date.
Do not let mixed-mode mornings quietly decide the whole day for you.
What matters here. The best version of this plan does not make you more compliant.
It makes you harder to stall. The goal is fewer invisible restarts, fewer quiet drops, and more judgment compounding across the system.
Sanitized But Real
What was deliberately blanked out of the fuller internal version
This is the part that should make it obvious the presentation copy is cut down, not invented.
The real version contains named excerpts, screenshots, and customer-context slices that are intentionally removed here.
Client Comparison
Comparative deliverable before / after excerpt
REDACTED
Workflow Diagram
Internal orchestration view excerpt
REDACTED
Meeting / Deal Note
Named transcript and promise stack excerpt
REDACTED
Sources
What this report is built from
Behavioral telemetry: the founder’s local Cowork.ai telemetry plus broader cohort/context telemetry used to sanity-check what looked founder-specific versus generally useful.
Voice layer: Superwhisper/voice transcript history, including deep-dive reads over 1,764 recordings and roughly 144,441 transcript words, plus transcript archival and ingestion work completed during the same period.
Daily reports across the discovery window: the two-week run of daily reports and end-of-day analysis, used as the narrative layer over the raw telemetry.
Custom augmentation: additional source material intentionally folded into the discovery, including Oura/body-state context, Superwhisper and meeting transcripts, architecture artifacts, and internal feedback lanes that were actively being pressure-tested.
Artifacts and systems: recent handoffs, repo state, report surfaces, system diagrams, decision logs, shared-brain state, Pinecone-backed memory work, git movement, and deliverables created in the same period.
Privacy posture: the report synthesis was run locally on the founder’s computer with enough RAM to keep source material on-device rather than pushing raw data into cloud processing.
Presentation metrics: several top-line counts in this public copy are modeled composites designed to preserve the operating shape after redaction, not act as compliance-grade ledger numbers.
Role-shaping note: this report is about a founder/operator and about the questions he was actively asking the system for feedback on. A support, sales, or ops report would use a different lens and different recommended installs.
Redactions: customer names, sensitive IP, specific internal prompts, and a few personal details were intentionally removed. The behavioral and workflow observations were not softened.
Prepared on March 25, 2026 by Moe [AI]. Public founder/operator discovery example, built from telemetry, daily reports, custom source augmentation, and report synthesis.